SQL Server utilizes replication agents to do
different tasks during the replication process. These agents are
constantly waking up at some frequency and fulfilling specific jobs. As
you can see in Figure 1,
several replication agent categories are listed under the Job Activity
Monitor when you expand the SQL Server Agents branch (SQL Server Agent,
Jobs, Job Activity Monitor branch).
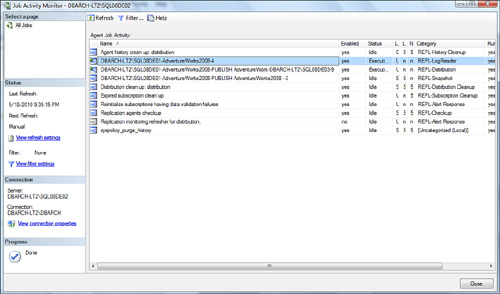
Here are the main replication agent categories:
Snapshot Agent
Log Reader Agent
Distribution Agent
Merge Agent (for updating subscribers)
History Cleanup Agent
Distribution Cleanup Agent
Expired Subscription Cleanup Agent
Reinitialize Subscriptions Having Data Validation Failures Agent
Replication Monitoring Refresher for Distribution Agent
Replication Agent Cleanup Agent
The Snapshot Agent
The snapshot agent is
responsible for preparing the schema and initial data files of published
tables and stored procedures, storing the snapshot on the distribution
server, and recording information about the synchronization status in
the distribution database. Each publication has its own snapshot agent
that runs on the distribution server. It takes on the name of the
publication within the publishing database within the machine on which
it executes (that is, [Machine][Publishing database][Publication Name]).
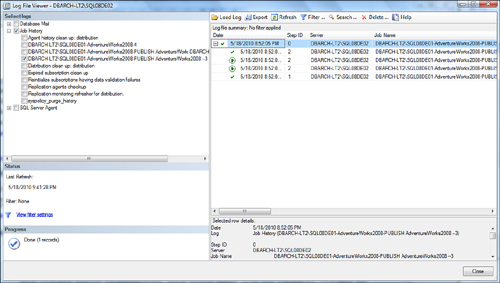
Figure 19.19
shows what this snapshot agent looks like under the SQL Server Agent,
Job Activity Monitor branch in SQL Server Management Studio (SSMS). The
snapshot agent (REPL-Snapshot category name) is named DBARCH-LT2\SQL08DE01-AdventureWorks2008-PUBLISH AdventureWorks2008 – Tra-1.
In addition, these agents can be referenced from the Replication
Monitor option (when you launch the Replication Monitor by
right-clicking from the Replication branch in SQL Server Management
Studio). Most often you are likely to use the SQL Server Agent path to
these agents though.
It’s worth noting that
the snapshot agent might not even be used if the initialization of the
subscriber’s schema and data is done manually.
The Snapshot Agent Synchronization
The snapshot agent is the process that ensures both databases start on an even playing field. This process is known as synchronization.
The synchronization process is performed whenever a publication has a
new subscriber. Synchronization happens only one time for each new
subscriber. It ensures that database schema and data are exact replicas
on both servers. After the initial synchronization, all updates are made
via replication.
When a new server subscribes to a publication, synchronization is
performed. When synchronization begins, a copy of the table schema is
copied to a file with the .sch extension.
This file contains all the information necessary to create the table
and any indexes on the tables, if they are requested. Next, a copy is
made of the data in the table to be synchronized and written to a file
(or several files) with the .bcp extension.
The data file is a BCP, or bulk copy file. Both files are stored in the
temporary working directory on the distribution server.
After the synchronization
process has started and the data files have been created, any inserts,
updates, and deletes are stored in the distribution database. These
changes are not replicated to the subscription database until the
synchronization process is complete.
When the synchronization
process starts, only new subscribers are affected. Any subscriber that
has been synchronized already and has been receiving modifications is
unaffected. The synchronization set is applied to all servers waiting
for initial synchronization. After the schema and data have been
re-created, all transactions that have been stored in the distribution
server are sent to the subscriber.
When you set up a subscription, it is possible to manually load the initial snapshot onto the server. This is known as manual synchronization.
For extremely large databases, it is frequently easier to dump the
database and then reload the database on the subscription server. If you
load the snapshot this way, SQL Server assumes that the databases are
already synchronized and automatically begins sending data
modifications.
Snapshot Agent Processing
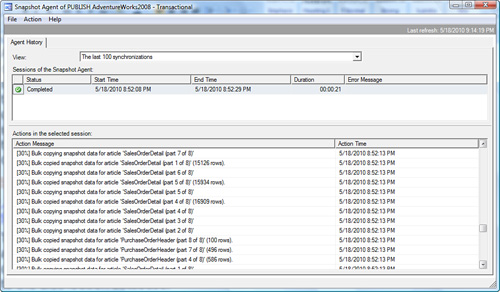
Figure 2
shows the details of the snapshot agent execution for a typical push
subscription. You can see the execution history by simply right-clicking
the snapshot job and choosing View History.
The following sequence of tasks occurs with the snapshot agent:
The
snapshot agent is initialized. This initialization can be immediate or
at a designated time in the company’s nightly processing window.
The agent connects to the publisher.
The agent generates schema files with the .sch
file extension for each article in the publication. These schema files
are written to a temporary working directory on the distribution server.
These are the create table statements and such that will be used to
create all objects needed on the subscription server side. They exist
only for the duration of the snapshot processing.
All
the tables in the publication are locked (held). The lock is required
to ensure that no data modifications are made during the snapshot
process.
The
agent extracts a copy of the data in the publication and writes it to
the temporary working directory on the distribution server. If all the
subscribers are SQL Server machines, the data is written using a SQL
Server native format, with the .bcp file extension. If you are replicating to databases other than SQL Server, the data is stored in standard text files with the .txt file extension. The .sch file and .txt files/.bmp files are known as a synchronization set. Every table or article has a synchronization set.
Caution
It’s important to make sure
you have enough disk space on the drive that contains the temporary
working directory. The snapshot data files will potentially be huge, and
this size is the most common reason for snapshot failure.
As you can see in Figure 3,
the agent executes the object creations and bulk copy processing at the
subscription server side in the order in which they were generated (or
it skips the object creation part if the objects have already been
created on the subscription server side and you have indicated this
during setup). This process takes awhile, so it is best to do this in an
off time so as not to impact the normal processing day. Network
connectivity is critical here. Snapshots often fail at this point.
The
snapshot agent posts the fact that a snapshot has occurred and what
articles/publications were part of the snapshot to the distribution
database. This is the only information sent to the distribution
database.
When
all the synchronization sets are finished being executed, the agent
releases the locks on all the tables of this publication. The snapshot
is now considered finished.
The Log Reader Agent
The
log reader agent is responsible for moving transactions marked for
replication from the transaction log of the published database to the
distribution database. Each database published using transactional
replication has its own log reader agent that runs on the distribution
server. It is easy to find because it takes on the name of the
publishing database whose transaction log it is reading ([Machine name][Publishing DB name]) and the REPL-LogReader category. Figure 19.19 shows the log reader agent (REPL-LogReader category name) for the AdventureWorks2008 database. It is named DBARCH-LT2\SQL08DE01-AdventureWorks2008-4.
After initial
synchronization has taken place, the log reader agent begins to move
transactions from the publication server to the distribution server. All
actions that modify data in a database are logged to the transaction
log in that database. This log is used not only in the automatic
recovery process, but also in the replication process. When an article
is created for publication and the subscription is activated, all
entries about that article are marked in the transaction log. For each
publication in a database, a log reader agent reads the transaction log
and looks for any marked transactions. When the log reader agent finds a
change in the log, it reads the changes and converts them to SQL
statements that correspond to the action taken in the article. The SQL
statements are then stored in a table on the distribution server,
waiting to be distributed to subscribers.
Because replication is based
on the transaction log, several changes are made in the way the
transaction log works. During normal processing, any transaction that
has either been successfully completed or rolled back is marked
inactive. When you are performing replication, completed transactions
are not marked inactive until the log reader process has read them and
sent them to the distribution server.
Truncating and fast
bulk-copying into a table are nonlogged processes. In tables marked for
publication, you cannot perform nonlogged operations unless you
temporarily turn off replication.
Note
One of the major
changes in the transaction log comes when you have the Truncate Log on
Checkpoint option turned on. When this option is on, SQL Server
truncates the transaction log every time a checkpoint is performed,
which can be as often as every several seconds. With replication, the
inactive portion of the log is not truncated until the log reader
process has read the transaction.
The Distribution Agent
A distribution agent
moves transactions and snapshot jobs held in the distribution database
out to the subscribers. This agent isn’t created until a push
subscription is defined for a subscriber. The distribution agent takes
on the name of the publication database along with the subscriber
information ([Machine name][Publication DB name ][Subscriber machine name]). If you look back at Figure 19.19, you see a distribution agent (the REPL-Distribution category name) for the AdventureWorks2008 database to a subscriber. It is named DBARCH-LT2\SQL08DE01--AdventureWorks2008 - PUBLISH AdventureWork - DBARCH-LT2\SQL08DE03-9, where SQL08DE01 is the publisher and SQL08DE03 is the subscriber.
Those not set up for
immediate synchronization share a distribution agent that runs on the
distribution server. Pull subscriptions, to either snapshot or
transactional publications, have a distribution agent that runs on the
subscriber. Merge publications do not have a distribution agent at all.
Rather, they rely on the merge agent, discussed next.
In transactional
replication, the transactions have been moved into the distribution
database, and the distribution agent either pushes out the changes to
the subscribers or pulls them from the distributor, depending on how the
servers are set up. All actions that change data on the publishing
server are applied to the subscribing servers in the same order they
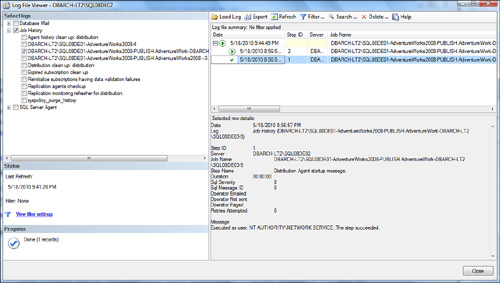
were incurred. Figure 4
shows the latest history of the distribution agent and the total
duration of the current subscription (11:20:56:4830000 hours, minutes,
seconds, milliseconds in this example).
The Merge Agent
When you are dealing with
merge publications, the merge agent moves and reconciles incremental
data changes that occur after the initial snapshot was created. Each
merge publication has a merge agent that connects to the publishing
server and the subscribing server and updates both as changes are made.
In a full merge scenario, the agent first uploads all changes from the
subscriber where the generation is 0 or greater than the last generation
sent to the publisher. The agent gathers the rows in which changes were
made, and the rows without conflicts are applied to the publishing
database.
A conflict can arise when
changes are made at both the publishing server and subscription server
to a particular row(s) of data. A conflict resolver handles these
conflicts. Conflict resolvers are associated with an article in the
publication definition. These conflict resolvers are sets of rules or
custom scripts that can handle any complex conflict situation that might
occur. The agent then reverses the process by downloading any changes
from the publisher to the subscriber. Push subscriptions have merge
agents that run on the publication server, whereas pull subscriptions
have merge agents that run on the subscription server. Snapshot and
transactional publications do not use merge agents.
Other Specialized Agents
In Figure 1, you can see that several other agents have been set up to do house cleaning around the replication configuration:
Agent history clean up: Distribution—
This agent clears out agent history from the distribution database
every 10 minutes (by default). Depending on the size of the
distribution, you might want to vary the frequency of this agent.
Distribution clean up: Distribution—
This agent clears out replicated transactions from the distribution
database every 72 hours by default. This agent is used for snapshot and
transactional publications only. If the volume of transactions is high,
the frequency of this agent should be adjusted downward so you don’t
have too large of a distribution database. However, the frequency of
synchronization with subscribers drives this frequency adjustment.
Expired subscription clean up—
This agent detects and removes expired subscriptions from the published
databases. As part of the subscription setup, an expiration date is
set. This agent usually runs once per day by default. You don’t need to
change this frequency.
Reinitialize subscriptions having data validation failures—
This agent is manually invoked. It is not on a schedule, but it could
be. It automatically detects the subscriptions that failed data
validation and marks them for re-initialization. This can then
potentially lead to a new snapshot being applied to a subscriber that
had data validation failures.
Replication monitoring refresher for distribution—
Microsoft SQL Server Replication Monitor is designed to efficiently
monitor a large number of computers. The queries that Replication
Monitor uses to perform calculations and gather data are cached and
refreshed on a periodic basis. Caching reduces the number of queries and
calculations required as you view different pages in Replication
Monitor and allows monitoring to scale well for multiple users. Cache
refresh is handled by the Replication monitoring refresher for
distribution agent. This job runs continuously, but the cache refresh schedule is based on waiting a certain amount of time after the previous refresh:
If
there were agent history changes since the cache was last created, the
wait time is a minimum of 4 seconds or the amount of time taken to
create the previous cache.
If
there were no agent history changes since the cache was last created,
the wait time is a maximum of 30 seconds or the amount of time taken to
create the previous cache. You don’t need to change this frequency.
Replication agents checkup—
This agent detects replication agents that are not actively logging
history. This checkup is critical because debugging replication errors
is often dependent on an agent’s history that has been logged.